|
Filtering File Systems - Then Things You Should Know
(By: The NT Insider, Volume 16, Issue 1, Jan-Feb 2009 | Published: 09-Mar-09| Modified: 09-Mar-09)
Regardless of whether you are still supporting legacy file system filter drivers, or maintaining or building new mini-filter drivers, there are some common techniques (ok, there are only nine?) you can use to improve the robustness of your filter. Many of these are pragmatic - they are not things you will read in the documentation, they come from experience working with filters for many, many years.
Never Trust Buffers
Filter drivers are forced to endure a remarkably hostile environment, both from their neighbors (other filter drivers) as well as those that are inherently untrusted (any user mode code). A single mistake in a file system filter driver can create a potential "time bomb" waiting to happen.
User Buffers are the most commonly identified "risk factor" when it comes to buffer management. Despite that, we still routinely see filters that fail to take the two necessary steps for protecting against user buffers. First, you must ensure that a user buffer really is within the user portion of the address space. This is performed by probing the address, normally using ProbeForRead or ProbeForWrite.
Probing a user buffer only ensures it is in the user's address space, however. If it is invalid at that point in time the probe will work, but this call does nothing to ensure the address remains valid. Thus, the second key part of buffer handling is to ensure any access to it is protected with a structured exception handler. Microsoft provides their own custom handler and it is invoked using special extensions implemented by the C compiler used in the WDK environment. This is done using __try and __except.
Both of these steps are essential to ensuring correct user buffer handling.
In addition, file system filter drivers must deal with the pragmatic issue that they may be handed invalid kernel data structures. The harsh reality is that it is not uncommon for other kernel components to pass along invalid structures. Mini-filters are somewhat protected against this, since invalid structures passed into filter manager will cause filter manager to crash, not the mini-filter. Despite this, if you are the only mini-filter on the system it won't crash without your filter and it will crash with your filter (and we all know that this means it must be "your fault").
Thus, what we generally suggest - as much as possible - is to carefully validate your own data structures. While not guaranteed, we've used this technique to detect erroneous situations numerous times. In our experience it is better to use "deprecated" functions like MmIsNonPagedSystem AddressValid (which is of dubious value) to add even a modest amount of robustness to our code. This is pragmatic - if the system crashes in our driver, we will be blamed for the crash. If we can instead return an error and it crashes in another driver, it will become the problem of that other driver writer. Remember, when someone types "!analyze -v", it will blame the first non-Microsoft driver on the stack. Hence, it-s better to not be on the stack, at least from a support overhead burden.
Validate Parameters
Sure, we all know that it isn't necessary to validate buffers that are passed to us by other kernel mode components, but only Microsoft has the luxury of this type of magic thinking. For the rest of us, it really is vital to keep in mind that the system is not static and we are constantly forced to "figure out" why things are not working.
Keep in mind when validating any information:
- Buffers are not static. You do not own the only reference to that buffer and they can (and do) change. If you want to rely upon the contents of buffers, you must capture that information (if it changes inside a private captured buffer, it's called "memory corruption" and not a buffer handling error!)
- With Windows Vista, MDLs that arrive in your filter can include "dummy pages". These pages can create potential confusion for any filter that tries to modify the data (e.g., an encryption filter) because that buffer's content is not static. This merely reinforces our observation before - if you want static content, capture it and operate on it separately from the original.
If you decide to switch around the MDLs in an I/O request, don't forget to also update the UserBuffer field (the file systems rely upon this being "correct" - which means it must be the same virtual address that is in the MDL passed).
Beware the Failure Cases
Over the years, we have consistently observed that developers are, as a group, remarkably optimistic. This shows in their coding, which tends to assume that everything is going to work properly. As it turns out, however, this optimism is unwarranted - and the source of frequent bugs. Further, as your driver is more widely deployed, you will observe a greater number of these failure scenarios.
Indeed, in our experience, even mature code bases will experience "we've never seen this failure case before" scenarios. Naturally, the fact that it is almost impossible to test all of these failure scenarios further complicates writing code to handle those cases. Nevertheless, it is important for file system filter driver writers (both legacy and mini-filter writers) to think about error cases and handle them.
In general, we've noticed a few classes of such failures:
- Allocation failures. These are quite common, but something often overlooked is that handling allocation failures at the point you need the allocated object is frequently "too late" to handle the error gracefully. Generally, we suggest moving the allocation to an earlier point in the code - keeping in mind that freeing an object won't fail. So, in a mini-filter (for example) we allocate our data structure for our context tracking information in the pre-create path, even though we won't use it until the post-create path. If we don't need it, we free it. In the pre-create path, however, we can gracefully return an error. In post-create, we are forced to try and cancel the file open (which is far more complicated and subject to errors).
- Connection failures. While we'll mention redirectors "later", we have noticed that timeouts and disconnections are common enough failures that just aren't handled. If you use a service, you have to consider what your driver will do when it fails, not to mention how it fails. Nothing is worse for a user than the frustration of having an operation (in your filter) hang forever waiting on a service that has entered an infinite loop.
- Unwinding failures. These are perhaps the most insidious of the error handling cases. You've done your job and checked for a specific error case. But you have already done operations that need to be undone. Thus, your error handling code must then attempt to undo something you've already done. It could be as simple as changing the read-only bit on a file, or as complicated as changing its ACL. Some later step fails and you attempt to set it back - but that attempt to unwind itself fails.
Of course, our point is not to provide some complete list, but rather to point out that when writing code, and particularly when code reviewing it, try looking through it and ignoring the "everything works right" cases and look at the "everything comes unraveled" cases. After all, the "everything works right" case is by far the most likely case to be tested and fixed quickly.
Avoid Changing File Sizes
The most difficult filters to build and maintain are those that change the size of the underlying file and then try to mask this behavior from the applications. There are very good reasons for masking these changes from applications - after all, applications rely upon the size information in the directory entry being correct. For example the "verify" option for xcopy ("/v") actually looks at the size in the directory entry, not in the file itself.
Exacerbating this issue is that directories can be surprisingly large (we've received bug reports against directories with over 700,000 entries in a single directory - so large that the owner of that large directory could not enumerate it with Explorer and instead only enumerated it from the command line!) If you have to actually open the file in order to retrieve the file size, it will make directory enumeration dramatically slower. In our experience, unless you implement caching, the cost of "correcting directory entry sizes" has an amazing impact - it effectively makes doing almost anything with high access directories impossible (e.g., "\Windows").
Underlying this is the fact that application programs are sloppy - they use information that is demonstrably not updated (NTFS, for example, only updates the size in the link used, so this size from the directory entry trick can be spoofed by using a link to change the file size).
We have seen people try to use "naming tricks" to resolve this issue. Fair warning: whenever you think you have a clever solution in a filter driver, ask yourself "and how will this work when someone else implements a filter driver that plays the same/similar trick." If the answer is "it does not work" then you don't have a viable solution. Name prefix/suffix tricks fall into this category.
The best thing to do is to never change size. If you must change the size of the file, the next best trick is to do this only on file systems that support both sparseness and alternate data streams - then you can keep a dummy default stream ("::$DATA" on NTFS) that is the correct size, with the modified data in an alternate data stream. Unfortunately, that often is not a viable solution because it is restricted to only some file systems. In that case, be prepared for building a very complicated filter driver.
FSD/MM/CC Interactions Are Complicated
We often observe that interactions in this business between the components are horribly complicated (See Figure 1). File system filter drivers sit in the midst of this complex environment and must be written to handle the ramifications of those interactions.
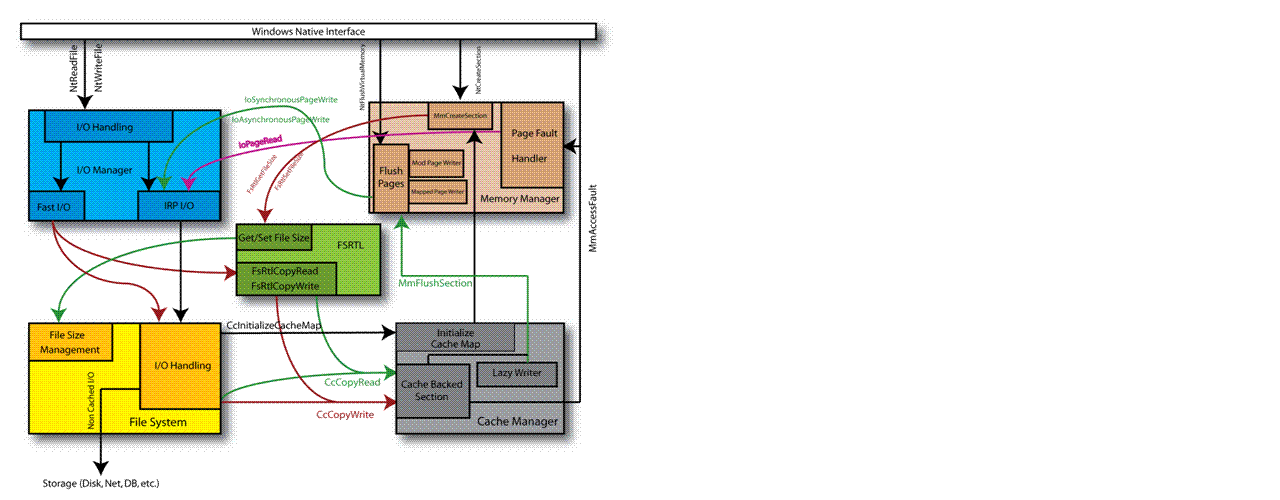
Figure 1
The simplest way to handle these interactions is to simply ignore them - in other words, don't get involved in the data flow through the system. That is definitely the simplest solution. Many filters must become involved in this in at least some fashion, however. Filters that are involved in I/O operations need to understand these interactions.
Still, it is beyond the scope of this article to describe these complexities. The point, however, is that in order to build a robust file system filter driver, you really do need to understand the file system.
Redirectors Do Not Behave Like Local File Systems
Some filters can restrict themselves simply to a single file system (e.g,. NTFS) or perhaps to a class of file systems (physical file systems) but many filters must handle the network as well. Over the years, the pattern we have observed is that filters are often written to target NTFS first and only once working against NTFS are they moved to other file system.
Sadly, this approach fails horribly when it comes to the network file systems. Filters that "work fine" on NTFS frequently exhibit serious problems when moved to the Windows redirector. Indeed, over the years, we've observed that it is often better to start with the network case and then move to NTFS - its generally a far less painful move than vice versa, particularly because project management often assumes that "once it works on NTFS we're almost done."
Some of the issues we have seen when it comes to filtering network redirectors over the years include:
-
Naming. Nothing in the local file system arena prepares you for the hideous complexity of naming in the network. Effectively, file names may be aliased due to hard links (which at least exist for physical file systems) but also due to overlapping shares not to mention special names sent by DFS to the redirector.
-
Context. On a local file system, it is rather easy to track unique instances of a given stream ("stream" is the NTFS terminology. On FAT, there is only a single stream within a file, but in NTFS there can be many streams within a single file). This is typically done using the FsContext parameter of the file object. Legacy filters may do this directly (via a lookup table keyed from this value) or indirectly (via a "filter context" that is attached to a list within the FsContext structure). Mini-filters rely upon Filter Manager; Filter Manager in turn relies upon filter contexts. The Windows redirector, however, does not necessarily use the same context even for two file objects pointing to the same file. This works correctly for them, but it violates this basic assumption in many filter drivers. Further complicating this, the network file systems may coalesce file objects together - changing their FsContext values when it detects two instances of the same file. Filters, once again, must be able to handle this particular case.
-
Relative open "issue". IoCreateFileSpecifyDevice ObjectHint (in at least some still in-use versions) has an issue when performing a relative open over the Windows redirector. In our experience, it is necessary to always construct "fully qualified path names" and send these into this API - or any API (e.g., FltCreateFile and its progeny) that relies upon it.
Let's not lose sight of the fact that there are also two other network redirectors that ship with at least one version of Windows ("in the box") - WebDAV (the http protocol for "distributed authoring and versioning") and NFS (which is shipped as part of the Vista and Server 2008 distributions, although versions were previously available as "Services for Unix").
Maybe You Need to Support Systems Older Than Windows 7
As difficult as it is for those in Redmond to believe, there are still a few stragglers left using Windows versions prior to Windows 7 (please don't miss the sarcasm, though the point is still valid). There are various reasons for this, but the biggest driver really is the cost associated with upgrading the systems. Particularly when those systems are performing their primary function properly, there is no compelling reason. People that do not need transactions, bit locker, resizable thumbnails, fancy graphical features and the like and instead are focused on executing custom software solutions, running embedded devices, etc. are very resistant to upgrading their systems.
In spite of this resistance, they do expect their anti-virus products, quota managers, content control managers, backup components, encryption products, etc. to work on their version of Windows. Microsoft does not receive revenue from old versions of Windows, but those of us building filter drivers receive revenue from building products for those older versions. This creates a constant tension between the general development community (that needs support for any version that is still in use by their customer base) and the desires of Microsoft (which is to move the platform forward so their customers will buy an upgrade).
The harsh reality is that we have a huge number of versions of Windows to support. Microsoft wants everyone to move to mini-filters (and has clearly stated they will enforce this at some point, which seems as if it will just force the legacy support to go "underground"). Each new platform requires additional resources to test and fix bugs - there are always changes in behavior, often for very specialized usage cases (transactions come to mind) that can directly impact on your own development (transactions matter to filters because filters see the "forward" operations but see no I/O if the transaction is aborted - even though the state of the underlying system changes).
Testing is Difficult
We can give you a basic list of the "tools of the trade" but the bottom line is that no matter how much testing you perform, you will never be able to cover every case. In all fairness, debugging a problem that manifests itself via an application - perhaps a common one like "Explorer" (common but still amazingly frustrating) or perhaps something far less common, like "Avid Newscutter Nitris DX" - is always going to be rather challenging to debug because it often requires that you determine why the application fails - you know it is related to something you are doing, but you don't know what it is.
Microsoft does not provide us with a conformance test. The closest thing we have (the ifskit tests) have mysterious failure modes and are often as inscrutable to understand as any failing application. Indeed, we generally do not investigate "SEV2" issues because we've found they generally are of the "oh, we don't work the same way that NTFS does in this case" category.
Another tool we often point out to people is the "FileTest" utility. It allows you to exercise uncommon operations like "open by file ID" that can be difficult to simulate with an off-the-shelf program, but need to work properly within your filter driver.
I/O Stress can be useful for finding issues in your I/O handling paths. Driver Verifier is a must - if you aren't using it during development and part of your testing, you aren't doing a good job. However, you must also test without Driver Verifier enabled. We've even seen cases where Driver Verifier has tests that only trigger on single processor computers!
At OSR, we have our own testing framework - it's a scripting language that is built against the native API and allows us to trivially write scripts that can test the native windows API. If you restrict yourself to the Win32 API, your tests will definitely be deficient, since it is a subset of the functionality in the native API.
Finally, don't forget to test via the network - but this time, with the file SERVER running over your filter. Again, you will see different behavior. For example, the SL_INDEX_SPECIFIED option that is used for directory enumeration is difficult to trigger - but does show up with some versions of the Windows file server software. Naturally, this is exercised when you access files over the network. Oh, and lest you missed this fact, you now (beginning with Server 2003) need to test between machines - loopback mode has been optimized out so that it bypasses the normal client/server model (allegedly there is a registry parameter to disable this functionality, but usually we find it easier to simply tell test organizations to use two computers, since that's going to be the most common configuration "in the field").
Don't Forget Plugfest
For anyone working with file system filter drivers should always plan on attending the periodic 'Plugfest' that Microsoft sponsors to aid interoperability. While the opportunity to do direct developer-to-developer interop testing is invaluable, the contacts - both Microsoft and third party vendors - are often more valuable. The events are sponsored by the file systems filtering team at Microsoft and are done directly at the Microsoft main campus. These events are publicized in a variety of ways, including via OSR's well regarded NTFSD mailing list, a highly technical discussion group talking about the development of file systems and file system filter drivers for Windows."
Conclusions
File system filter drivers are the most complicated type of filter driver to write on Windows; deceptively, they span a very broad range, from "simplistic" (a surprising number of examples fall into this category) to "more complicated than a file system driver". There are many reasons for this and we've tried to touch on some of them. But if you are building a file system filter driver because you think it will be "simpler" than a file system driver, you are likely to be unpleasantly surprised.
If you can achieve your functionality without a filter driver, we would suggest doing it in that way. A real filter driver is truly a challenge to build.
This article
was printed from OSR Online http://www.osronline.com
Copyright 2017 OSR Open Systems Resources, Inc.
|