|
Back to Basics - An Introduction to Transactions
(By: The NT Insider, Vol 14, Issue 1, January - February 2007 | Published: 02-Feb-07| Modified: 02-Feb-07)
The advent of kernel-level transactions in Vista has received considerable coverage at recent Microsoft events. The introduction of transactions will substantially impact those of us who operate in the file systems space. File systems developers must decide what level of support they will give to transactions in their own file systems, and writers of file system filter drivers must make fundamental decisions about how to handle transactions in their own drivers.
However, in talking to individual developers after some of these events, we discovered that some of you take for granted that transactions are well understood, when in fact they're not. Given that this is an essential part of working in the Windows Vista file systems arena, we've taken it upon ourselves to write a simple primer for describing how a basic transactional system works. By no means are we trying to write a comprehensive description of all issues in this area because that would be a book, not an article.
At the base of any transactional system is a mechanism for managing recovery. Recovery is the process of restoring the state of the system to a known consistent point. In the file systems space, you typically do this by using a log. You write entries into the log to keep track of what must be done to restore the state of the system; we refer to these individual entries as records. We will refer to a collection of related records as a single transaction. Typically, different types of records tell you what needs to be done:
-
Start Records indicate when a new transaction is initiated. Such records can be explicit, or they can be implicit (meaning, the first record of a new transaction indicates the start of the transaction).
-
Redo Records indicate what changes must be performed to restore the consistent state of the system as it should be at the end of the transaction.
-
Undo Records indicate what changes must be performed to restore the consistent state of the system as it should be at the beginning of the transaction
-
End Records indicate that all the changes for the specific transaction have been written into the log.
These records comprise a basic set of building blocks that you can then use to construct your transactional system. Underlying all of this is the assumption that you start with some state of the system that is consistent (which is defined by your system, not by the log) and the set of changes lead to another consistent state. The system might be inconsistent between these two points, but using the information in the log it can be restored back to one of these consistent states. From the perspective of the log, whether you use the redo information (to roll forward) or the undo information (to roll backward) isn't important because it is the consistent state that is of interest. Other parts of the system do care about whether something rolls forward or backward, so once an End Record is written, you would expect the log recovery to roll forward.
For the parts of the system using this log, there are some additional requirements to make this work right:
-
Persistent changes to the data cannot be made before the relevant log record is written. If a change is to be written before the End Record, there must be an Undo Record written to the log before the change is written. It is common for logs to support only Redo Records, in which case data changes cannot be made persistent until the End Record has been written to the log.
-
No changes to the data can be visible outside the transaction before the End Record has been written. Generally, this is accomplished using serialization (locking).
-
The log must have strong persistence guarantees. When we write to the log, we need to know that the records have really been written to disk.
A key concept to think about in how logs work is that they are trying to protect against specific types of failure, such as a system crash. The information in the log must always allow the system to be restored to a consistent state regardless of where the crash occurs. In work we've done in the past, we would test crash consistency by simulating crashes at all possible states; we would snapshot the disk after every disk block level change and verify that we can restore the system to a consistent state.
Of course, for improved efficiency, you can have multiple simultaneous operations. Provided that the changes are independent, you can have multiple transactions. The records for each of these could be written into separate logs, or they could be commingled into a single common log; each technique is valid, and whichever one you use depends on the environment in which you are implementing this functionality.
To augment your log, let's assume that you have a recovery process. This is a means by which you can process the records that make up a transaction and restore the consistent state. A recovery process is invoked whenever it is needed, such as in the case where a system crash or some other error requires restoring the system to a consistent state.
The recovery process must interpret the contents of the log records and apply them as appropriate - that is, based on whether the End Record is found in the log for the specific transaction.
Once you have some mechanism for providing recovery, you can combine that with the actual operations to provide the traditional transactional semantics:
-
Atomicity. A transaction is an atomic unit and either "all occurs" or "none occurs." There should be no intermediate (and inconsistent) states.
-
Consistency. The system should be in a consistent state before and after the transaction completes.
-
Isolation. The changes while a transaction is in progress are not visible to anyone who is not participating inside the transaction; indeed, it is this property that makes things interesting for file systems folks.
-
Durability. Once a transaction is committed, the state of the system will not "roll back" to a state - even a consistent state - before that point in time.
With your log in place, you can actually implement such a system in isolation fairly easily. This "ease" is relative because transactional systems are actually a challenge to implement and verify.
With a system like this in place, you can implement a variety of recoverable schemes. For example, you now have a solution to the traditionally complex issue of dealing with renaming in a file system. If you look at the various schemes for performing a rename operation, clearly there's no way to perform a series of discrete steps in which the system is consistent at all points in time (if you could, you wouldn't need transactions!). Because using a disk check program is time-consuming - you have to look at all the on-disk state, not just the state that was changing because you don't know what was changing - a transactional system provides an ideal mechanism for describing the set of steps that need to be taken and how to make the system consistent just in case something goes wrong.
This approach is taken by journaling file systems - such as NTFS on Windows, JFS on IBM's AIX, the original Cedar file system that used database journaling for consistency, ext3 on Linux, Episode in DCE/DFS, plus numerous others at this point - and is concerned about protecting metadata and ensuring that it remains consistent.
However, such systems have some limitations. For example, they focus on solving a specific problem such as consistency for their file system, and not providing a general-purpose solution to user applications. Database systems have traditionally provided robust, full-featured transactional mechanisms for database-driven applications. The problem they solve is allowing discrete resources to be used within a single controlling transactional architecture.
The log scheme that we described is sufficient for a single-point entity. This scheme is usually referred to as one-phase commit because it does not require coordination between multiple independent components. If you want to extend this to allow multiple independent components, you need to have some additional mechanism in place to provide coordination between each entity.

Figure 1 - One Phase Commit
The traditional solution to coordinating activities between multiple distinct components is to use what is known as two-phase commit (and yes, there is a three-phase commit, but we won't talk about it here). The two-phase commit environment combines two or more components, each of which provides its own isolation environment, like the one described earlier, to provide consistent behavior between these components. At this point we should define our terms a bit better:
-
Resources. These are the individual pieces that own some persistent state. In the case of a file system, the file system is the resource. But this could be a database (such as the Registry) or any other component that has state.
-
Coordinator. This component is responsible for dealing with the individual resources.
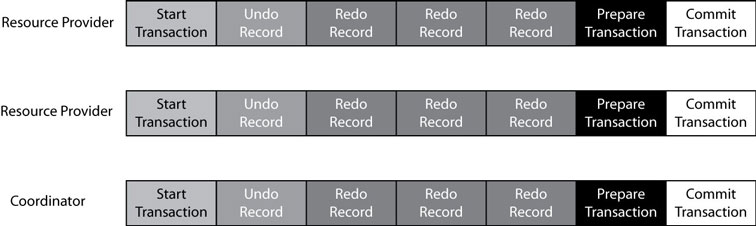
Figure 2 - Two Phase Commit
A Coordinator provides the infrastructure for implementing transactions between the various Resources. In its own way, it behaves very much like the Resources -it has some sort of recoverable store (the log described earlier) but rather than record changes in data, it records the results of communications with the Resources.
A Coordinator initiates a transaction and communicates with the individual Resources. Each Resource is responsible for providing its own recoverable store; although they might share a common log, they are each responsible for defining the correct behavior for their own resources. Changes are made in each Resource as necessary to implement the higher-level operation.
When the changes are complete and the transaction is ready to be completed, the Coordinator notes this fact in its own log -this is generally known as a Prepare. The Coordinator then sends a Prepare message to each Resource. A Resource can, at that point, acknowledge the Prepare, which means the Resource can commit the transaction. The key here is that once the Resource has agreed to the Prepare, it cannot fail the operation later. But because other Resources still need to agree to the Prepare, the Resource cannot commit its transaction either (that is, it cannot write the End Record to its own log).
Generally, at this stage the Resource ensures it has everything it needs to roll forward the transaction. If the Resource later decides it was wrong and cannot actually perform the necessary work, it has violated its guarantee - and essentially has corrupted the transaction. This is really no different than if the disk were to fail and such problems are not "fixed" by a transactional system.
After all the Resources have acknowledged the Prepare, the Coordinator can then record its own End Record ("commit") for the transaction. It follows up and sends the commit message to each of the Resources.
If a Resource terminates between the Prepare and the Commit, it must query the Coordinator and ask what the outcome was for this transaction. Based on the results, it will either abort or commit its own transaction.
In this fashion, you can use multiple different Resources and yet provide transactional behavior.
Transactions, and the use of transactions, are motivated by providing a model for handling failures. From our own work in file systems space, we know that failures - and handling failures appropriately - is an essential part of the development process and one that often is more complex than handling the "normal" cases. Transactional systems don't make handling failures and errors simpler, but they force you to always think through the failures in advance rather than resolve them in an ad hoc fashion.
A future article will delve into the details of transactions and how they are actually implemented in Windows Vista.
This article
was printed from OSR Online http://www.osronline.com
Copyright 2017 OSR Open Systems Resources, Inc.
|