When Windows NT was first conceived one of its major design goals was to support symmetric multi-processing. In order to accomplish this the developers of NT had to design into the operating system primitives, which would allow code to synchronize access to data structures. The primitives they gave us are events, semaphores, mutexes, executive resources, and spin locks. While we will touch many of the afore mentioned synchronization primitive in this article, the primitive most important to us as Windows 2000 device driver writers are spin locks. Why? Because as device driver writers, we are potentially faced with synchronizing access to data that can be accessed by code running at different I/O Request Levels (IRQLs). In this article, we will go over the motivation for synchronization, what spin locks are, and how they are implemented by Windows 2000 on both uni-processor and multi-processor systems.
The Need for Locking
In a multi-processor environment consider the following scenario: Two processors, Processor A and Processor B are executing the same piece of code as described in Table 1 below. This code is used to update a shared reference count (let’s assume the reference count starts at zero). Let’s see what happens:
|
Processor A |
Processor B |
|
1. Read reference count |
1. Read reference count |
|
2. Update reference count |
2. Update reference count |
|
3. Write reference count |
3. Write reference count |
Table 1 – Unsynchronized Execution
Since both processors are executing the same code simultaneously, both processors read the reference count value, which is initially zero, at the same time. Then both processors increment their copies of the Reference count and finally write back the result. Is this correct? Of course not, both processors have incremented their own copies of the reference count to 1 and have written 1 back as the final result, not 2 as it should be. How can we correct this behavior? Let’s consider rewriting the code running on Processor A and Processor B using a synchronization primitive, as described in Table 2.
|
Processor A |
Processor B |
|
1. Acquire synchronization primitive protecting reference count |
1. Acquire synchronization primitive protecting reference count |
|
2. Read reference count |
2. Read reference count |
|
3. Update reference count |
3. Update reference count |
|
4. Write reference count |
4. Write reference count |
|
5. Release synchronization primitive protecting reference count |
5. Release synchronization primitive protecting reference count |
Table 2 – Synchronized Execution
In this scenario both Processor A and Processor B attempt to acquire the synchronization primitive protecting the reference count. Since only one processor can succeed in acquiring the synchronization primitive at a time, let’s say that Processor A succeeds in acquiring it. What happens to Processor B? It just waits until Processor A releases the synchronization primitive. Processor A on the other hand is now guaranteed that it can read, modify, and update the reference count without worrying about Processor B. Therefore Processor A reads the reference count, updates the reference count to 1 and writes the reference count back, before releasing the synchronization primitive. Now Processor B gains access to the synchronization primitive, reads the reference count value, which is now 1, updates the reference count to 2, writes back the value and releases the synchronization primitive. Voila, the correct answer 2. So as you can see, in a multi-processor environment, synchronization primitives are necessary to synchronize access to shared data. So, the need for synchronization between two threads of control is clear. The question now becomes how that synchronization can be implemented. Windows 2000 provides several mechanisms for implementing synchronization among threads of control. These include dispatcher objects, and spin locks. In the next section, we’ll consider when each of these is appropriate.
Dispatcher Objects
Dispatcher objects, which include events, semaphores, and mutexes, are useful for synchronizing access between multiple threads of execution. However dispatcher objects are only usable when the system is in a Dispatchable state. A processor is dispatchable when the IRQL of the processor is less than DISPATCH_LEVEL, this allows a Dispatch Interrupt to occur so that the Dispatcher can schedule another thread. For example, a mutex could be used to protect the reference count used in the previous example, In this case a thread that wants to manipulate to the reference count would first need to acquire the mutex by calling KeWaitForSingleObject(). If the mutex cannot be acquired, the caller will be blocked until the mutex becomes available. So, in the following example (Table 3) if both Thread A and Thread B were executing simultaneously, one of the threads executing Step 1, the KeWaitForSingleObject() would succeed in acquiring the mutex, while the other thread would block.
|
Thread A |
Thread B |
|
1. KeWaitForSingleObject() |
1. KeWaitForSingleObject() |
|
2. Increment reference count |
2. Increment reference count |
|
3. KeReleaseMutex() |
3. KeReleaseMutex() |
Table 3 – Synchronizing Using a Mutex
Why are dispatcher objects only useful when the system is dispatchable? Because attempting to wait for a dispatcher object to become available via KeWaitForSingleObject()/KeWaitForMultipleObject() can result in a dispatch operation occurring. If we’re at an IRQL >= DISPATCH_LEVEL (and, by the way, did not input a timeout value of 0) Win2K will bugcheck with a stop code of IRQL_NOT_LESS_OR_EQUAL (0x0A) because the dispatcher interrupt cannot be serviced.
So what do we do if the data structures we want to synchronize have to be accessed at IRQL DISPATCH_LEVEL or DIRQL? We can’t wait use the events, semaphores, mutexes or executive resources because we are not allowed to cause a dispatch operation while running at elevated IRQL. The answer is to use spin locks.
What is a Spin Lock?
A spin lock is a standard Win2K data structure normally allocated out of non-paged pool. Every spin lock has an IRQL associated with it. When a driver attempts to acquire the lock on an SMP system, the IRQL of the current processor is raised to the IRQL of the spin lock and the system then attempts to acquire the lock. If the lock is not immediately available, the processor attempting to acquire the spin lock will actually busy wait (spin) until the lock is available. Figure 1 shows a diagram of how a spin lock is acquired.
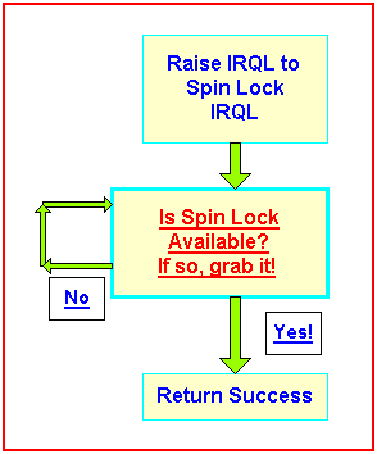
Figure 1 – Acquiring a Spin Lock
As you can see before attempting to acquire the lock, the spin lock acquisition code raises the IRQL of the processor to the IRQL associated with the spin lock. We’ll talk about what IRQL that is in just a minute. Then it spins in a loop attempting to acquire the lock, using an atomic test and set instruction. Once the spin lock is acquired your code continues executing at the IRQL associated with the spin lock.
The reader should note a couple of things about spin locks:
1. There is no return from spin lock acquisition code until the lock is available.
2. There are no timeout semantics. Therefore the processor spins until the lock is acquired.
3. There is no way to check the spin lock state before attempting to acquire the spin lock.
4. Spin locks are not recursively acquirable. If you have already acquired the lock you must not try to acquire it again.
Releasing a spin lock is shown in Figure 2.
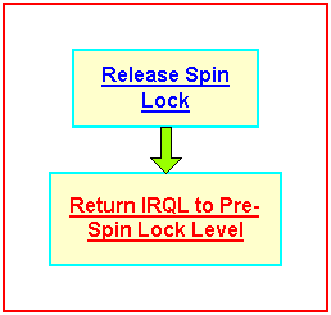
Figure 2 – Releasing a Spin Lock
The spin lock release code performs the action necessary to release the lock and then returns the IRQL of the processor to its pre spin lock acquisition level. Pretty simple so far!
Two Kinds of Spin Locks
Spin locks in Win2K come in two flavors, executive spin locks and ISR spin locks. Executive spin locks have the following characteristics:
· The IRQL associated with the spin lock is DISPATCH_LEVEL
· The lock is allocated by the driver and must be allocated from non-paged pool
· Is initialized via KeInitializeSpinLock().
· It is acquired via KeAcquireSpinLock().
· It is released via KeReleaseSpinLock().
While ISR spin locks have the following characteristics:
· The IRQL associated with the spin lock is DIRQL (i.e., the Synchronize IRQL specified in the IoConnectInterrupt() call).
· The Lock is either allocated and initialized by the driver, or allocated automatically by the IoConnectInterrupt() call.
· The I/O Manager automatically acquires the Lock before the ISR is entered and automatically releases the Lock after the ISR is exited. This ensures that your ISR can only be executing on one Processor at a time.
· The Lock can be acquired by the Driver by calling KeSynchronizeExecution(). It is automatically released upon return from KeSynchronizeExecution()
They both sound pretty easy to use, and for the most part they are. If you have to synchronize access to some data used by both your dispatch routines and your DPC routine then you use an executive spin lock (i.e. you use KeAcquireSpinLock()/KeReleaseSpinLock()). If you have to synchronize access to some data between your DPC and/or dispatch routines and your ISR you use an ISR spin lock (i.e. you use KeSynchronizeExecution()).
So, now that we’re in sync (what a punster….) let’s talk about using spin locks in a driver. First and foremost the most important design consideration is to design in synchronization from the start. To do that, you look at the data and/or hardware that you’re using and determine which threads of execution need to access which resources and at what IRQL. Given this, you can determine whether or not you need to use dispatcher objects, executive spin locks and/or ISR spin locks. Further more you may discover that we may need or want to use different synchronization primitives to protect different resources. For example, consider the case where you keep both some statistics and an internal queue of IRPs in our device extension. You could have one lock protect both fields but that would mean that while any code is updating the statistics, other code wanting to manipulate the queue could possibly be spinning waiting to acquire the same lock or visa-versa. Sounds like a pretty inefficient design to me. A more efficient approach would be to have separate locks protecting the queue and the statistics. Therefore the any code that updates the statistics or the queue could be executing simultaneously in a multi-processor environment! The reader should understand however the pitfalls associated with using multiple locks. Consider the following scenario in Table 4 while executing in a multi-processor environment.
The code running on Processor A acquires spin lock Foo while the code executing on Processor B acquires spin lock Bar. Then the code running on Process A attempts to acquire spin lock Bar, but has to spin because the Bar spin lock was already acquired by the code running on Processor B. Meanwhile the code on Processor B attempts to acquire spin lock Foo, but it has to spin because Processor A already acquired the Foo spin lock. Both of these processors are now deadlocked! How can we avoid this?
Avoiding Deadlock
Well, the easiest solution is only use one lock, but maybe that doesn’t work in your design. If one lock doesn’t work in your design, then what I recommend is for you to come up with a locking hierarchy. What’s a locking hierarchy? It is a strategy that you design that indicates a predefined order of lock acquisition. Simply put, it says that if we need to modify data protected by spin lock Foo and also modify data protected by spin lock Bar, we will always acquire spin lock Foo before acquiring spin lock Bar. So, let’s recode Table 4 using our locking hierarchy.
|
Processor A |
Processor B |
|
1. Acquire spin lock Foo |
1. Acquire spin lock Bar |
|
2. Acquire spin lock Bar |
2. Acquire spin lock Foo |
|
3. Twittle Foo and Bar bits |
3. Twittle Foo and Bar bits |
|
4. Release spin lock Bar |
4. Release spin lock Foo |
|
5. Release spin lock Foo |
5. Release spin lock Bar |
Table 4 – Processor Deadlock
As you can see in Table 5 we have now avoided the deadlock that was shown in Table 4. This is because both Processors are now acquiring the locks in our predefined locking hierarchy. This is pretty simple stuff, so it is strange to me why the DDK says to avoid using multiple locks. Now, it may be obvious, but I want to point something. As I mentioned earlier I said that you only had to acquire spin locks Foo and Bar in the correct order if you needed to modify the data protected by those locks at the same time. If you only have to modify data protected by the Bar spin lock, then you only need to acquire the Bar spin lock, or if you only have to modify data protected by the Foo spin lock, then you only need to acquire the Foo spin lock. So, in most cases, your driver will probably only have to acquire one lock at a time, thus increasing the parallelism of your driver.
|
Processor A |
Processor B |
|
1. Acquire spin lock Foo |
1. Acquire spin lock Foo |
|
2. Acquire spin lock Bar |
2. Acquire spin lock Bar |
|
3. Twittle Foo and Bar bits |
3. Twittle Foo and Bar bits |
|
4. Release spin lock Bar |
4. Release spin lock Bar |
|
5. Release spin lock Foo |
5. Release spin lock Foo |
Table 5 – Avoiding Deadlock with Locking Heirarchy
Uni-Processor Systems
Now that we’ve talked about how spin locks are implemented you must be wondering what good, if any, they do on a uni-processor. Remember above how we said a spin lock was implemented? Let me refresh your memory, I said that the spin lock acquisition code raised the IRQL of the processor to the IRQL associated with the spin lock and then sat in a tight loop attempting to acquire the lock. This is fine on a multi-processor machine, but this is crazy on a uni-processor, why spin and wait if there is no other processor to compete with? Well, Win2K doesn’t, on a uni-processor Win2K machine raising IRQL is sufficient to synchronize access. Think about it. If all the spin lock acquisition code does, on a uni-processor, is raise the IRQL, then the only other code that can execute is code that is called to respond to interrupts at IRQLs greater than the current IRQL. So, if my driver is running on a uni-processor machine and if it uses a spin lock to synchronize access to some data that both my dispatch routines and DPC use, just raising IRQL will be sufficient to ensure that only my dispatch routines or my DPC will be accessing the data at one time. So that’s why there are two NTOSKRNLs on a Win2K Distribution. NTOSKRNL.EXE is the uni-processor version and NTKRNLMP.EXE is the multi-processor version. Pretty clever.
Summary
As you can see Win2K provides sufficient primitives to allow driver writers to create multi-processor safe code. The trick is to design it in from the start and to create a design, which minimizes the time spent under lock, in order to promote parallelism and interactivity. Also important is for the driver writer to understand under what conditions synchronization primitives such as dispatch objects or spin locks can be used.


 Post Your Comment
Post Your Comment