As part of our continuing series of articles on Windows data structures, this article discusses Splay Trees. A splay tree is a type of binary search tree, invented by Daniel Sleator and Robert Tarjan, which has the additional feature of rebalancing itself to make the most recently accessed node the root of the tree. This feature means that frequently accessed nodes will be located nearer the root of the tree where they can be accessed more quickly.
For kernel-mode programming, the standard Installable File System (IFS) include file "ntifs.h" (which is distributed in the WDK starting with Windows Vista) contains the RTL_SPLAY_LINK data structures and routine definitions necessary to initialize and manipulate splay trees.
The Basics
Splay trees are defined by one or more entries, where each entry is a node in the splay tree. A node consists of three pointers named Parent, LeftChild and RightChild. Where Parent, if set, points to the parent node, and LeftChild and RightChild point to child nodes that have some user defined relationship to each other and to the parent, for example a greater than or less than relationship. Figure 1 illustrates this concept.
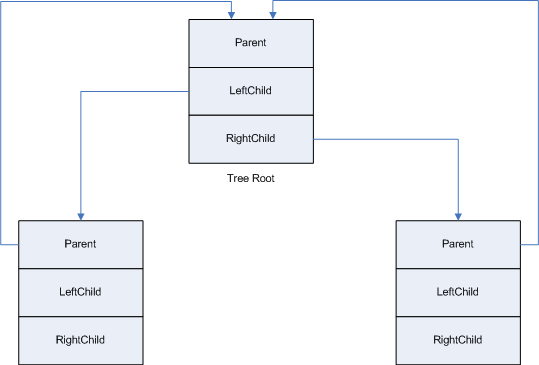
Figure 1 - Windows Splay Tree
Entries in the splay tree consist of a splay tree header followed by user-defined data. A splay tree header in Windows is defined by the RTL_SPLAY_LINKS structure which is defined as follows (in ntifs.h):
typedef struct _RTL_SPLAY_LINKS {
struct _RTL_SPLAY_LINKS *Parent;
struct _RTL_SPLAY_LINKS *LeftChild;
struct _RTL_SPLAY_LINKS *RightChild;
} RTL_SPLAY_LINKS;
typedef RTL_SPLAY_LINKS *PRTL_SPLAY_LINKS;
Splay links are initialized using the RtlInitializeSplayLinks(Parent) macro. This macro performs the following operation, SplayLink->Parent = Parent, SplayLink->LeftChild= SplayLink->RightChild=NULL. Each entry to be added to the splay tree should be defined to contain a RTL_SPLAY_LINKS field. This field will be used to add the structure to the splay tree. You can define your own structure to insert in a splay tree as follows:
typedef struct _MYSPLAYNODE {
//
// Splay Link to be used to insert this node
// into my splay tree.
//
RTL_SPLAY_LINKS SplayInfo;
//
// Data definition that I am using to build
// splay node relationships..
//
ULONG Value;
} RTL_SPLAY_LINKS;
typedef RTL_SPLAY_LINKS *PRTL_SPLAY_LINKS;
Initializing a Splay Tree
Unlike Windows doubly-linked lists ("Windows Linked Lists" The NT Insider, Sept-Oct 2007), splay trees do not have the equivalent of a "list head" or any predefined structure that points to the start of the splay tree. An empty splay tree is just represented by a PRTL_SPLAY_TREE pointer set to NULL.
Next, let's talk about how you add a node to a splay tree.
Adding a Splay Tree Node
In order to add a node to a splay tree there are 3 steps that must take place. These steps are as follows:
- You search the tree looking for the proper place in the tree to insert a new node; where this insertion takes place is based upon some user-defined relationship
- You insert the new node as either a LeftChild or RightChild of the found node.
- You "splay" the tree around the new node, re-balancing the tree and making the new node the root of the tree.
To perform step 1, you traverse the tree looking for a node which most closely matches the user-defined relationship between nodes in the tree. Traversing the tree is done using the RtlLeftChild and/or RtlRightChild routines. Which routine is used depends on the new node?s relationship to the parent node. For example, if the new node was less than the parent you might traverse left using RtlLeftChild otherwise you would use RtlRightChild.
To perform step 2, you insert the new node, after its RTL_SPLAY_LINKS structure has been initialized with RtlInitializeSplayLinks, as a child of the located node using either the RtlInsertAsLeftChild or RtlInsertAsRightChild routines. As mentioned above, which routine you use depends upon the new node's relationship to the located node.
Finally to perform step 3, the user calls RtlSplay passing in the address of the new node just added to the tree so that the tree can be splayed around that node. This node will become the root of the tree.
Let's demonstrate an addition to the tree starting with Figure 2 . In this tree you will see that we have one node named, "Node 1" which contains a data value of 60. For our example, we will define our data relationships as follows: data whose value is greater than the value in a node will go to the left; and data less than the value in a node will go to the right: we will not allow duplicate values in the tree. Then what we will do is add a new node "Node 2" to the tree whose value is 64 and perform the 3 steps defined above.
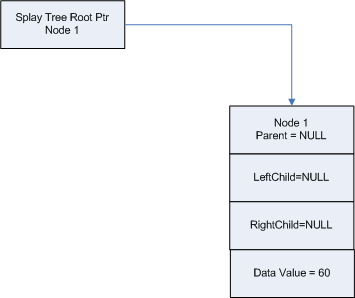
Figure 2 - Splay Tree with One Node
As you can see in Figure 3, we have added "Node 2" to the tree. It was added as a left child of "Node 1" because its value "65" was greater than the value of "60". Now that that node has been added we can call RtlSplay to rebalance the tree.
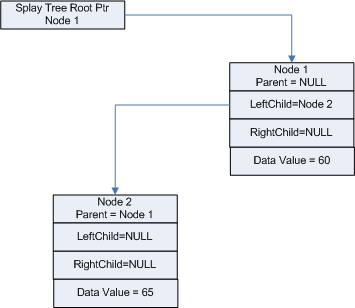
Figure 3 - Added New Node; Have Not Splayed Tree
As you can see in Figure 4, the tree has been rebalanced or "splayed" by the call to RtlSplay. In subsequent figures, we will combine the adding and the rebalancing of the tree in order to save trees. So for our next addition, we'll add "Node 3" whose data value is "63".
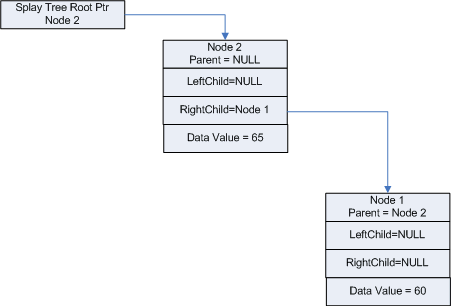
Figure 4 - Tree is Now Splayed
As you can see in Figure 5, "Node 3" containing value "63" has been added to the splay tree and has been rebalanced using RtlSplay. Let's proceed to add "Node 4" whose data value is "64", and call RtlSplay (See Figure 6).
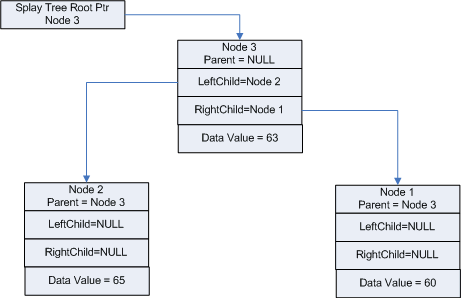
Figure 5 - Splay Tree After Adding Node 3 and Calling RtlSplay
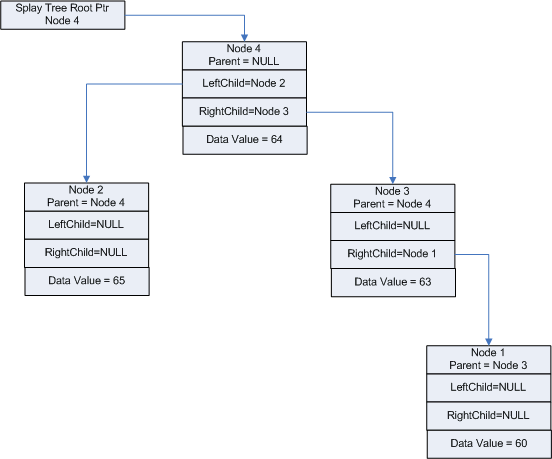
Figure 6 - Splay Tree After Adding Node 4 and Calling RtlSplay
So now that you've got a handle on how adding a node and splaying a tree works, let's talk about the other splay routines available. These routines are:
- RtlDelete - this routine deletes the node specified on input and then the tree is rebalanced. If for some reason you do not want the tree rebalanced, you can call RtlDeleteNoSplay.
- RtlIsRoot - this routine determines if the input node is the root of the splay tree.
- RtlParent - this routine returns the parent node of the input node.
RtlLeftChild, RtlRightChild - these routines return the left or right child of the input node.
- RtlIsLeftChild, RtlIsRightChild - these routines indicate whether the input node is the left or right child of its parent node.
- RtlRealPredecessor - This routine returns, if a given node has a left subtree, the rightmost node in the left subtree of the input node as the predecessor, if none exists NULL is returned. RtlSubtreePredecessor would return the same node in this case.
- RtlRealSuccessor - This routine returns, if a given node has a right subtree, the leftmost node in the right subtree of the input node as the successor, if none exists NULL is returned. RtlSubtreeSuccessor would return the same node in this case.
- RtlSubtreePredecessor - This routine returns, if a given node has a left subtree, the rightmost node of that subtree. If none exists, NULL is returned.
- RtlSubtreeSuccessor - This routine returns, if a given node has a right subtree, the leftmost node of that subtree. If none exists, NULL is returned.
As you can see, Windows provides a full set of APIs that can be used to implement splay trees. However one item that you must keep in mind is synchronizing access to the tree.
Synchronization of Splay Trees
Callers of the RTL splay tree functions are responsible for synchronizing access to the splay tree. What is used to synchronize access depends upon the IRQL used when accessing the list. If the IRQL is >= DISPATCH_LEVEL then spinlocks must be used and the nodes must be located in non-paged pool. Otherwise dispatcher objects, such as mutexes, semaphores, etc., can be used to synchronize access to the list and the entries can be in paged pool.
Because serializing access to your splay tree structure can have major performance implications on your implementation, you should consider your options carefully. For example, for accesses at IRQL PASSIVE_LEVEL you might want to consider using ERESOURCEs, to provide a mixture of shared and exclusive access options.
So... What are they good for?
We have spent a lot of time and paper explaining how splay trees work, but what we have not talked about is what they are good for. As any programmer should know, one type of data structure has both advantages and disadvantages when compared to any other. Each data structure can be evaluated on the basis of the following three criteria:
- Memory footprint
- Search time
- Administration overhead (i.e. adding, deleting, rebalancing, or other management overhead that is performed on the structure).
In terms of memory footprint each splay entry has an overhead of 3 pointers (If using the Generic Table Routines, discussed later in this paper, 2 more pointers are added to the memory footprint). This overhead could be considered high or low depending upon the overall size of the entry.
As for Search time, basic operations such as insertion, lookup, and removal take O(log n) amortized time. In other words, an entry in a table with 100 entries can be found in an average of about 7 operations, when the number of operations is amortized across all searches performed on the table. The down-side of splay trees is that their worst-case performance during search can be bad -- as bad as O(n) -- that is it can take 100 operations to find an specific entry in a 100 entry table. However, you need to balance this against the fact that frequently accessed nodes will move nearer to the root where they can be accessed quickly. Because of this feature splay trees are useful for implement things like caching algorithms.
One thing to note is that sequentially accessing all the elements in the tree can cause significant overhead if accessing each element in the tree causes splay. Yuck! As discussed in the section on Generic Tables, this overhead can be avoided by using the RtlEnumerateGenericTable WithoutSplaying.
As for administration an overhead hit is taken each time an entry is added, deleted, or accessed, since the tree must be splayed. However the overhead of these operations is more than compensated for by the decrease in access time of nodes in the tree.
Another Option - Generic Tables
After reading about splay trees, and seeing the various functions that Windows provides, you be thinking: "This seems like a lot of work", and it is. What many driver devs don't realize is that Windows uses splay trees to implement Generic Tables and most people who implement splay trees use the generic table routines. Some advantages of using the Windows generic table routines include:
- The generic table routines do all of the work for you. They splay the tree on access, delete, and addition. In addition, they provide routines to allow you to enumerate entries in the tree.
- If for some reason the splay tree algorithms are not providing the performance you require you can easily switch to AVL trees (named for using Adelson, Velsky and Landis, if you wondered) by putting the following define before "ntrtl.h" in your driver: "#define RTL_USE_AVL_TABLES 0".
- WinDbg provides debugging support for generic tables via the !gentable command.
The Windows generic table package provides a full set of APIs for managing splay trees, but at a higher level than the splay tree APIs. Generic tables are defined by a RTL_GENERIC_TABLE structure as defined below:
typedef struct _RTL_GENERIC_TABLE {
PRTL_SPLAY_LINKS TableRoot;
LIST_ENTRY InsertOrderList;
PLIST_ENTRY OrderedPointer;
ULONG WhichOrderedElement;
ULONG NumberGenericTableElements;
PRTL_GENERIC_COMPARE_ROUTINE CompareRoutine;
PRTL_GENERIC_ALLOCATE_ROUTINE AllocateRoutine;
PRTL_GENERIC_FREE_ROUTINE FreeRoutine;
PVOID TableContext;
} RTL_GENERIC_TABLE;
typedef RTL_GENERIC_TABLE *PRTL_GENERIC_TABLE;
RTL_GENERIC_TABLE's are initialized using the RtlInitializeGenericTable. The function definition is as follows:
VOID
NTAPI
RtlInitializeGenericTable (
PRTL_GENERIC_TABLE Table,
PRTL_GENERIC_COMPARE_ROUTINE CompareRoutine,
PRTL_GENERIC_ALLOCATE_ROUTINE AllocateRoutine,
PRTL_GENERIC_FREE_ROUTINE FreeRoutine,
PVOID TableContext
);
Where:
- Table is the address of the RTL_GENERIC_TABLE to initialize
CompareRoutine is the address of a Comparison routine which is used to compare entries in the tree and return
- TL_GENERIC_COMPARE_RESULTS which indicates how the nodes relate to each other.
- AllocateRoutine is the address of a routine used to allocate new entries for the table. Entries allocated will be at least sizeof(RTL_SPLAY_LINKS)+sizeof(LIST_ENTRY) + the size of any user data bytes long. In addition, the first sizeof(RTL_SPLAY_LINKS)+sizeof(LIST_ENTRY) bytes of the allocated memory are for use by the generic table routines.
- FreeRoutine is the address of a routine used to free memory when a node is deleted from the tree
- TableContext is a a context value, which can be null, which is stored in the RTL_GENERIC_TABLE structure and is accessible by the Compare, Allocate, and Free routines.
The generic table package provides the following routines to help you with your implementation:
- RtlDeleteElementGenericTable - This routine uses the CompareRoutine to find an element in the tree and once found, calls the FreeRoutine to delete the found node. The tree is rebalanced after this call.
- RtlEnumerateGenericTable - This routine flattens the table by converting it from a splay tree to an order link list. To avoid flattening the table, users should instead call
- RtlEnumerateGenericTableWithSplaying to preserve the splay tree layout.
- RtlEnumerateGenericTableWithoutSplaying - This routine, called repeatedly, enumerates the nodes contained within the generic table, and preserves the layout of the splay tree. This routine is multi-processor safe and more efficient that RtlEnumerateGenericTable.
- RtlGetElementGenericTable - This routine is used to retrieve a pointer to node in the tree by index value, e.g. 1, 2, 3, etc. The zeroth element is retrieved by using index 0 and the last node in the tree is accessed by using RtlNumberGenericTableElements()-1. The indexes of entries change over time as nodes are added and deleted from the tree. A safer and more efficient method of accessing nodes in the tree is by using RtlLookupElementGenericTable.
- RtlInsertElementGenericTable - This routine adds a new node to a generic table. The routine takes as input the address of the data to be copied to the new element, the size of the new element to add if added, and the address of a location to receive a BOOLEAN value indicating whether or not the new node was inserted in the table. If the new element was not inserted into the generic table, then the value of this routine will be the address of the matching element.
- RtlLookupElementGenericTable - This routine looks up a node in the table which contains same data as the input data to this routine. If no match is found, this routine returns NULL.
- RtlNumberGenericTableElements - This routine returns the number of nodes contained within the generic table.
- RtlIsGenericTableEmpty - This routine returns TRUE, if the generic table is empty. It returns FALSE otherwise.
As with the splay tree APIs, callers of the generic table functions are responsible for synchronizing access to the table. The same guidance applies, as previously described in the section on Synchronization.
Summary
As you can see splay trees are a great construct to use when you need fast lookup. In addition, they provide the added benefit of allowing you to switch between splay and AVL trees easily if you use generic tables to implement your tree, and WinDbg support is provided.


 Post Your Comment
Post Your Comment