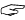If you've been working in kernel-mode on Windows for any significant amount of time, you've almost certainly encountered Structured Exception Handling (SEH). Basically, SEH is the standard kernel-mode exception handling mechanism that's built into Windows. Because support within the O/S with no way to access it doesn't make much sense, Microsoft compilers provide access to the O/S's exception support via the __try and __except keywords.
To make SEH work, cooperating support must be provided by the compiler, hardware, and OS. Precisely how SEH is implemented on a particular platform can vary based on architecture. Information on how SEH is implemented on the x86 is readily available. In fact, it's likely that you've stumbled upon a variation of this construct at least once while stepping through assembly code in the debugger:
push 0x17708
push 0x173f4
mov eax,fs:[00000000]
push eax
mov fs:[00000000],esp
Once you see a sequence like this, it's a clear tip-off that the function uses SEH. It's also possible to use this information to locate all of the possible exception handlers within the routine.
In debugging driver code on the x64, I noticed that I never saw those telltale sequences, I couldn't help wondering what was going on. How does Windows implement exception handling on the x64?
Huh?
If you're already confused, then this article might not be for you. To get up to speed on how x86 exception handling is implemented, I recommend reading "A Crash Course on the Depths of Win32 Structured Exception Handling" by Matt Pietrek, which appeared in the January 1997 issue of the Microsoft Systems Journal. While understanding how x86 exception handling is implemented isn't absolutely necessary to understand this article, it provides a good starting point to understand the differences between x86 exception handling and the x64 implementation.
x64 - A Chance to Trim the Fat
Because on the x86 each function that uses SEH has this aforementioned construct as part of its prolog, the x86 is said to use frame based exception handling. There are a couple of problems with this approach:
-
Because the exception information is stored on the stack, it is susceptible to buffer overflow attacks.
-
Overhead. Exceptions are, well, exceptional, which means the exception will not occur in the common case. Regardless, every time a function is entered that uses SEH, these extra instructions are executed.
Because the x64 was a chance to do away with a lot of the cruft that had been hanging around for decades, SEH got an overhaul that addressed both issues mentioned above. On the x64, SEH has become table-based, which means when the source code is compiled, a table is created that fully describes all the exception handling code within the module. This table is then stored as part of the PE header. If an exception occurs, the exception table is parsed by Windows to find the appropriate exception handler to execute. Because exception handling information is tucked safely away in the PE header, it is no longer susceptible to buffer overflow attacks. In addition, because the exception table is generated as part of the compilation process, no runtime overhead (in the form of push and pop instructions) is incurred during normal processing.
Of course, table-based exception handling schemes have a couple of negative aspects of their own. For example, table-based schemes tend to take more space in memory than stack-based schemes. Also, while overhead in the normal execution path is reduced, the overhead it takes to process an exception is significantly higher than in frame-based approaches. Like everything in life, there are trade-offs to consider when evaluating whether the table-based or a frame-based approach to exception handling is "best."
Seeing It for Yourself
So, how is table-based exception handling implemented on the x64? It just so happens that all of the data structures and functions involved in SEH on the x64 are documented as part of the SDK. Not uncharacteristically, the documentation tends to be a bit terse, and at times it only provides structure definitions. This article explores this information in a more practical manner.
Exception Directory and RUNTIME_FUNCTIONs
Within a PE image there are various directories that contain information about the image. For example, if the image has any exports, there will be an export directory that describes the exports. In the case of an x64 image, there happens to be an exception directory that contains a variable number of RUNTIME_FUNCTION structures, listed below:
typedef struct _RUNTIME_FUNCTION {
ULONG BeginAddress;
ULONG EndAddress;
ULONG UnwindData;
} RUNTIME_FUNCTION, *PRUNTIME_FUNCTION;
Note the use of ULONGs for addresses even though we're talking about a 64-bit architecture. This is because the values contained in the structure are offsets from the base of the image and not addresses or pointers. Now let's describe each field in turn.
BeginAddress - This value represents an offset into the image where some bit of code of interest to SEH begins. This is an incredibly vague description that will (hopefully) become clearer as we move along.
EndAddress - This value represents an offset into the image where some bit of code of interest to SEH ends. This is an incredibly vague description that will (hopefully) become clearer as we move along.
UnwindData - This value is an offset from the base of the image to an UNWIND_INFO structure that describes why the bit of code encompassed in the BeginAddress and EndAddress is of interest. The UNWIND_INFO structure is defined in Figure 1.
|
#define UNW_FLAG_NHANDLER 0x0
#define UNW_FLAG_EHANDLER 0x1
#define UNW_FLAG_UHANDLER 0x2
#define UNW_FLAG_CHAININFO 0x4
typedef struct _UNWIND_INFO {
UBYTE Version : 3;
UBYTE Flags : 5;
UBYTE SizeOfProlog;
UBYTE CountOfCodes;
UBYTE FrameRegister : 4;
UBYTE FrameOffset : 4;
UNWIND_CODE UnwindCode[1];
union {
//
// If (Flags & UNW_FLAG_EHANDLER)
//
OPTIONAL ULONG ExceptionHandler;
//
// Else if (Flags & UNW_FLAG_CHAININFO)
//
OPTIONAL ULONG FunctionEntry;
};
//
// If (Flags & UNW_FLAG_EHANDLER)
//
OPTIONAL ULONG ExceptionData[];
} UNWIND_INFO, *PUNWIND_INFO;
Figure 1 - UNWIND_INFO Structure
|
For the sake of brevity (and actually achieving something with this article) I'm going to limit the scope of our discussion to UNWIND_INFO structures that describe exception handlers, which are those that have the UNW_FLAG_EHANDLER bit set. So called "unwind handlers" and "chained handlers" are going to have to wait for a later issue.
So, where was I...Oh, that's right...If the UnwindData has the UNW_FLAG_EHANDLER bit set, then the BeginAddress and EndAddress fields of the RUNTIME_FUNCTION describe the location of a function in the image that uses SEH. The UnwindData structure then is going to describe all the places where the __try keyword appears in the function, their associated exception handlers (a.k.a. exception filters), and the location of the code contained in the __except block. Be sure to note the distinction between the exception handler and the exception block itself - the handler determines if the __except block is executed or not.
The two members of the UNWIND_INFO structure that relate directly to exception handling are ExceptionHandler and ExceptionData. So, next we'll look at these two in a bit more detail. Incidentally, the CountOfCodes and UnwindCode array are also important and interesting, but, again, that's fodder for another article.
Yes! More Data Structures
When the UNW_FLAG_EHANDLER bit is set, the ExceptionHandler field of the UNWIND_INFO structure is assumed to be valid. This field is filled in by the compiler and says, "Hey, you, O/S! If an exception ever occurs and the instruction pointer is >= BeginAddress and < EndAddress, call this handler!" This generic exception handler, currently implemented as _C_specific_handler, is then responsible for figuring out exactly what to do with this exception. It does this by parsing the ExceptionData.
On the x64, the ExceptionData is actually an offset to a pointer to a SCOPE_TABLE structure (defined in ntx64.h in build 5308 of the Windows Driver Kit):
typedef struct _SCOPE_TABLE {
ULONG Count;
struct
{
ULONG BeginAddress;
ULONG EndAddress;
ULONG HandlerAddress;
ULONG JumpTarget;
} ScopeRecord[1];
} SCOPE_TABLE, *PSCOPE_TABLE;
As you can see, this is a variable length structure containing a count followed by Count "scope records". While the RUNTIME_FUNCTION describes the entire range of a function that contains SEH, the SCOPE_TABLE describes each of the individual __try/__except blocks within the function. Let's check out each of the fields of the scope record in turn:
BeginAddress - This value indicates the offset of the first instruction within a __try block located in the function.
EndAddress - This value indicates the offset to the instruction after the last instruction within the __try block (conceptually the __except statement).
HandlerAddress - This value indicates the offset to the function located within the parentheses of the __except() statement. In the documentation you'll find this routine called the "exception handler" or "exception filter".
If the code in question specifies the predefined handler EXCEPTION_EXECUTE_HANDLER, this value may simply be "1" (i.e. the value of EXCEPTION_EXECUTE_HANDLER).
JumpTarget - This value indicates the offset to the first instruction in the __except block associated with the __try block.
The Result
Putting all of the foregoing info together, Figure 2 shows the data structure that we're going to be dealing with for the remainder of the article.
|
Figure 2 - RUNTIME_FUNCTION with UNW_FLAG_EHANDLER FUNCTION Set |
Example
Checking out an example of how this all fits together should help clear up what the structures that we've seen so far represent. Consider this function:
VOID
FrobThePointer(
PUCHAR UserAddress
) {
__try {
*UserAddress = 0;
*UserAddress = 1;
} __except (EXCEPTION_EXECUTE_HANDLER) {
DbgPrint("Bad Address\n");
}
}
Using instruction address zero as the base, the resulting assembly looks something like what you see in Figure 3.
|
<00> mov [rsp+0x8],rcx
<05> sub rsp,0x28
<09> mov rax,[rsp+0x30] // Move UserAddress into RAX
<0e> mov byte ptr [rax],0x0 // *UserAddress = 0;
<11> mov rax,[rsp+0x30] // Move UserAddress into RAX
<16> mov byte ptr [rax],0x1 // *UserAddress = 1;
<19> jmp FrobThePointer+0x28 // Success!
<1b> lea rcx,"Bad Address\n" // Begin of code in except block...
// prepare to DbgPrint
<22> call DbgPrint
<27> nop
<28> add rsp,0x28
<2c> ret
Figure 3 - Assembly of FrobThePointer |
During the compilation process, the RUNTIME_FUNCTION (See Figure 4) would be put into the exception directory of the driver's PE header. Note that the numbers here are again based on the previous, zero based example for clarity.
|
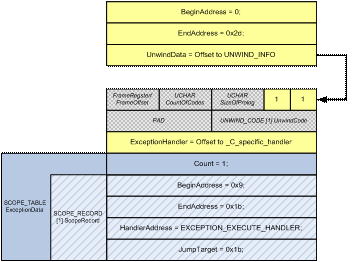
Figure 4 - RUNTIME_FUNCTION for FrobThePointer |
As you can see, this structure fully describes the SEH used within this function. By looking at the SCOPE_TABLE we know that:
-
There is one __try/__except block in this function.
-
The __try block begins at address 0x9 and ends at 0x1b.
-
The developer provided the default exception filter of EXCEPTION_EXECUTE_HANDLER, meaning always call the __except block.
-
The __except block can be found at address 0x1b.
If an exception occurs while dereferencing one of the pointers within the __try block, the function _C_specific_handler will be called and will begin parsing the ExceptionData. Once _C_specific_handler finds a scope record that covers the faulting instruction, it knows exactly where the exception handler and code for the __except block reside.
More About _C_specific_handler
Now let's take all of the info we've collected to put together the pseudo code for _C_specific_handler in Figure 5. Earlier I mentioned that the ExceptionHandler in the RUNTIME_FUNCTION is the compiler telling the O/S what to call if an exception is raised while executing the function. Once the exception is raised by the processor, the standard exception handling mechanism in Windows will find the RUNTIME_FUNCTION for the offending instruction pointer and call the ExceptionHandler. This will always result in a call to _C_specific_handler for kernel-mode code running on current versions of Windows. _C_specific_handler will then begin walking all of the SCOPE_TABLE entries searching for a match on the faulting instruction, and will hopefully find an __except statement that covers the offending code.
|
_C_specific_handler {
scopeTable = UwindData->ExceptionData;
For (index = 0; index < scopeTable->Count; index++)
scopeRecord = scopeTable->ScopeRecord[i];
If (FaultingInstruction >= scopeRecord->BeginAddress &&
FaultingInstruction < scopeRecord->EndAddress) {
If (scopeRecord->HandlerAddress != 1) {
callExceptHandler = (*scopeRecord->HandlerAddress)();
} else {
callExceptHandler = TRUE;
}
If (callExceptHandler) {
(*scopeRecord->JumpTarget)();
}
}
}
}
Figure 5 - Pseudo-code for _C_specific_handler |
Wanna Know More?
If you're dying to know more, all this information is readily available through your favorite debugger. Simply pass the function of interest to the .fnent command and all that's left is parsing the UNWIND_INFO structure. Also, don't forget this is fully documented in the SDK, along with various functions and structure definitions to make your spelunking that much more enjoyable.


 Post Your Comment
Post Your Comment